|
|

|
|
Quản lý, phân tích số liệu |
   |
|

|

|
| Trang chủ
>
Main menu
>
Phương pháp luận
>
Quản lý, phân tích số liệu | Bảng thuật ngữ Dịch tễ học và Thống kê | Xin chào các bạn,
Trong quá trình học
tập và làm việc liên quan tới Dịch tễ học và Thống kê chắc hẳn các
bạn đã từng được nghe hoặc biết đến các thuật ngữ như: Case-control
Study, Cohort Study, Cross-sectional Study, Chi Square, Crude odds ratio, vv.
Hay các thuật ngữ đươc viết tắt: OR, RR, EFp, EFe, vv. Hiện nay có
nhiều thuật ngữ được dịch khác nhau dựa trên những quan điểm nhìn
nhận khác nhau của các nhà Dịch tế và Thống kê học. Thongke.info xin
giới thiệu bảng thuật ngữ Dịch tễ học và Thống kê trên quan điểm
của thongke.info. BẢNG THUẬT NGỮ DỊCH TỄ HỌC VÀ THỐNG KÊ | Thuật ngữ tiếng anh | Dịch tiếng việt | Thuật ngữ tiếng anh | Dịch tiếng việt | | Adverse effect | Tác động bất lợi | False positive | Dương tính giả | | Alternative hypothesis | Giả thuyết thay thế | Fleiss
Quadratic | Phương
trình bậc 2 của Fleiss | | Analytic study | Nghiên cứu phân tích | Fleiss with CC | Chuẩn hóa liên tục theo Fleiss | | Analytical cross-sectional study | Nghiên cứu cắt ngang phân tích | Frequency | Tần số | | Approximation error | Sai số xấp xỉ | Hypothesis testing | Kiểm định giả thuyết | | Association | Sự tương quan | Independent variable | Biến độc lập | | Attributable
Fractions | Phân
số gán | Intervention study | Nghiên cứu can thiệp | | Bias | Sai số | Likelihood ratio of a positive test | Tỷ suất khả năng của một phép thử dương tính | | Byar
approx. Poisson | Kiểm
định Poisson ước tính Byar | Likelihood
Ratios | Tỷ
suất khả năng | | Byar
approximation | Ước
lượng Byar | Logistic regression | Hồi quy lô gíc | | Case report | Báo cáo trường hợp | Low birth weight ratio | Tỷ suất sinh nhẹ cân | | Case series | Loạt trường hợp (ca bệnh) | Mantel-Haenszel
chi square | Khi
bình phương Mantel-Haenszel | | Case-control study | Nghiên cứu bệnh-chứng | Mantel-Haenszel
Summary Chi Sqr | Khi
bình phương tóm tắt Mantel-Haenszel | | Chi
Square | Kiểm
định khi bình phương (X2) | Mantel-Haenszel
Summary Odds Ratios | Tỷ
suất chênh Mantel-Haenszel | | Clinical trial | Thử nghiệm lâm sàng | MH
Adjusted RR | Nguy
cơ tương đối được điều chỉnh theo MH | | Cluster Sampling | Chọn mẫu chùm | Morbidity | Tỷ lệ Bệnh trạng | | Cohort study | Nghiên cứu thuần tập | Multiple
continuous variables | Các
biến liên tục | | Community | Cộng đồng | Multiple regression | Hồi qui đa biến | | Conditional maximum likelihood estimate | Ước lượng khả năng cực đại có điều kiện | Negative confounding | Gây nhiễu âm tính | | Confounding | Gây nhiễu | Negative predictive value | Giá trị tiên đoán âm tính | | Confounding factor | Yếu tố gây nhiễu | Nonexposed | Không phơi nhiễm | | Confounding variable (Confounder) | Biến số gây nhiễu | Nonfatal | Không
chết | | Correlational study | Nghiên cứu tương quan | Nonparametric model | Mô hình phi tham số | | Cross-sectional study | Nghiên cứu cắt ngang | Normal approximation | Xấp xỉ chuẩn hóa | | Crude odds ratio | Tỷ suất chênh thô | Null hypothesis | Giả thuyết không hiệu lực (Ho) | | Crude
OR for Each Exposure Level | Tỷ
suất chênh thô cho mỗi một mức phơi nhiễm | Observational study | Nghiên cứu quan sát | | Cut-off point | Ngưỡng cut off | Outcome | Kết quả | | Density | Hàm mật độ | Output | Đầu ra | | Dependent variable | Biến phụ thuộc | Parameter | Tham số | | Descriptive cross-sectional study | Nghiên cứu cắt ngang mô tả | Parameterization | Tham số hóa | | Descriptive study | Nghiên cứu mô tả | Parametric model | Mô hình tham số | | Design
effect | Hiệu
lực thiết kế | Placebo | Giả dược | | Determinant | Yếu tố quyết định | Polytomous
multiple logistic Regression | Hồi
quy logic đa biến Polytomous | | Directly
Adjusted RD | Khác
biệt nguy cơ tương đối được điều chỉnh trực tiếp | Population | Quần thể | | Directly
Adjusted RR | Nguy
cơ tương đối được điều chỉnh trực tiếp | Population attributable risk | Nguy cơ quy chiếu quần thể | | Distribution | Sự phân bố | Positive confounding | Gây nhiễu dương tính | | Distribution function | Hàm phân bố | Positive predictive value | Giá trị tiên đoán dương tính | | Ecological study | Nghiên cứu sinh thái | Positive
association | Tương
quan dương tính | | Efficacy | Hiệu quả | Power | Lực mẫu | | Entropy | Động
lực học | Prevalence | Tỷ lệ hiện mắc | | Estimate | Ước lượng | Prevalence
difference | Khác
biệt tỷ lệ hiện mắc | | Estimation error | Sai số ước lượng | Prevalence ratio | Tỷ suất hiện mắc | | Etiologic
fraction in exposed(EFe) | Phân
số nhân quả trong nhóm phơi nhiễm | Proportion | Tỉ lệ | | Etiologic
fraction in pop.(EFp) | Phân
số nhân quả trong quần thể | Protective factor | Yếu tố bảo vệ | | Exact
Measures of Association | Kiểm
định tương quan chính xác | Protective
or negative association | Tương
quan bảo vệ hoặc âm tính | | Exposed | Bị phơi nhiễm | p-value | Giá trị p | | Exposure | Phơi nhiễm | Qualitative Research | Nghiên cứu định tính | | False negative | Âm tính giả | Quantitative Research | Nghiên cứu định lượng | | Random | Ngẫu nhiên | Trend line | Đường xu hướng | | Random measures | Đo lường ngẫu nhiên | True negative | Âm tính thật | | Random
number quality | Chất
lượng số ngẫu nhiên | True positive | Dương tính thật | | Random variables | Biến ngẫu nhiên | True
positive rate | Tỷ
lệ dương tính thật | | Randomness | Sự ngẫu nhiên | Two by two table | Bảng tiếp liên 2x2 | | Rate | Tỉ số | Two-sided | Hai chiều | | Rate difference | Khác biệt tỷ số | Two-sided
confidence interval | Khoảng
tin cậy cho kiểm định 2 chiều | | Rate ratio | Tỷ số tỷ suất | Unconditional
multiple logistic regression | Hồi
quy logic đa biến không điều kiện | | Receiver Operator Characteristic (ROC) Curve | Đường cong mô tả hoạt động của
bộ thu nhận | Uncorrected
chi square | Khi
bình phương chưa chuẩn hóa | | Restriction | Hạn chế | Variables | Biến số | | Retrospective | Hồi cứu | Variance | Phương sai | | Retrospective cohort study | Nghiên cứu thuần tập hồi cứu | Wilcoxon
signed-rank test | Kiểm
định xếp hạng Wilcoxon | | Risk | Nguy cơ | Yates
corrected chi square | Khi
bình phương chuẩn hóa Yates | | Risk
Difference | Khác
biệt nguy cơ tương đối | z-Score
and Exact Measures of Association | Điểm
Z-score và kiểm định tương quan chính xác | | Risk factor | Yếu tố nguy cơ | Ratio | Tỉ số | | Risk
Ratio | Tỷ
suất nguy cơ | Systemic error | Sai số hệ thống | | RxC
Table | Bảng
tiếp liên RxC | Systematic random sampling | Chọn mẫu ngẫu nhiên hệ thống | | Sample size | Cỡ mẫu | Stratified sampling | Chọn mẫu phân tầng | | Sampling technique | Kỹ thuật chọn mẫu | Statistical significance | Ý nghĩa thống kê | | Score
with Continuity Correction | Điểm
chuẩn hóa liên tục | Standard deviation | Độ lệch chuẩn | | Screen
negative, or positive | Sàng
lọc âm tính hoặc dương tính | Stable distribution | Phân bố ổn định | | Screening | Sàng lọc | Specificity | Độ đặc hiệu | | Selection bias | Sai số chọn lựa | Single
proportion | Một
tỷ lệ | | Sensitivity | Độ nhạy | Simple random sampling | Chọn mẫu ngẫu nhiên đơn |
Số lượt đọc:
10200
-
Cập nhật lần cuối:
14/11/2012 11:53:36 AM Hướng dẫn khôi phục dữ liệu sau khi gặp sự cố "corrupted"27/01/2013 11:11' PM Khi các bạn đang nhập liệu, nguồn của máy tính đột ngột bị mất (do lỏng đường dây, do mất điện đột ngột) mà bạn vẫn chưa kip lưu thì sau khi bạn khởi động lại máy tính và mở form epidata đang nhập liệu, máy tính sẽ báo lỗi như sau “One or more records are corrupted”.
Các bạn sẽ cố gắng tìm mọi cách để mở file đó ra, nhưng sẽ không thể mở được trực tiếp bằng phần mềm Epidata. Như vậy các bạn sẽ phải nhập lại toàn bộ số phiếu mình đã nhập trong form đó nếu bạn không có file backup.
Thongke.info xin giới thiệu với các bạn một cách rất đơn giản để khắc phục sự cố này. Thống kê và phương pháp phân tích số liệu - Sử dụng Stata12/01/2013 10:09' AM Xin chào các bạn, Xin chào các bạn,
- Khái niệm về thống kê cơ bản
- Lựa chọn trắc nghiệm thống kê
- Thực hành thống kê với Stata
Bài đã đăng: Những vấn đề cơ bản của thống kê thực hành30/10/2012 09:58' AM Thống kê thực hành không nhằm mục đích vào giải quyết những vấn đề lý thuyết của thống kê và thống kê toán. Thống kê thực hành bao gồm các nội dung của quá trình nghiên cứu thống kê cụ thể. Các nội dung này được tiếp cận nhất quán trên tư tưởng của thống kê toán, đặc biệt là phương pháp mẫu ngẫu nhiên trong nghiên cứu thống kê cũng như các công cụ cần thiết trong thực hành, nghiên cứu thống kê. Với mục đích nói trên, thống kê thực hành đề cập đến những nội dung cụ thể sau: Thống kê thực hành không nhằm mục đích vào giải quyết những vấn đề lý thuyết của thống kê và thống kê toán. Thống kê thực hành bao gồm các nội dung của quá trình nghiên cứu thống kê cụ thể. Các nội dung này được tiếp cận nhất quán trên tư tưởng của thống kê toán, đặc biệt là phương pháp mẫu ngẫu nhiên trong nghiên cứu thống kê cũng như các công cụ cần thiết trong thực hành, nghiên cứu thống kê. Với mục đích nói trên, thống kê thực hành đề cập đến những nội dung cụ thể sau: Thống kê mô tả26/10/2012 09:46' PM Thống kê mô tả luôn là cách thức mở đầu cho các phân tích thống kê nói chung và phân tích kinh tế xã hội nói riêng. Có nhiều cách hiểu và đánh giá vai trò của thống kê mô tả, với quan niệm thống kê mô tả là bước khai phá số liệu, các nội dung trong chương này trình bày thống kê mô tả với hai mục đích chính: một là, thống kê mô tả như một cách thức tổng hợp số liệu và mô tả các đặc trưng quan trọng của các biến; hai là, dùng thống kê mô tả phát hiện các đặc trưng và quan hệ tiềm ẩn trong tổng thể, đặc biệt là các quan hệ nhiều biến. Thống kê mô tả luôn là cách thức mở đầu cho các phân tích thống kê nói chung và phân tích kinh tế xã hội nói riêng. Có nhiều cách hiểu và đánh giá vai trò của thống kê mô tả, với quan niệm thống kê mô tả là bước khai phá số liệu, các nội dung trong chương này trình bày thống kê mô tả với hai mục đích chính: một là, thống kê mô tả như một cách thức tổng hợp số liệu và mô tả các đặc trưng quan trọng của các biến; hai là, dùng thống kê mô tả phát hiện các đặc trưng và quan hệ tiềm ẩn trong tổng thể, đặc biệt là các quan hệ nhiều biến.
Thongke.info xin giới thiệu với các bạn bài viết: thống kê mô tả, các bạn có thể download bài viết tại đây.
Thongke.info xin cám ơn PGS.TS Ngô Văn Thứ đã chia sẻ bài viết.
Phương pháp kiểm định tương tác trong phân tích số liệu nghiên cứu khoa học - Assessment of Interaction02/08/2012 09:36' AM Giới
thiệu
Đôi
khi, mối liên quan giữa hai biến bị thay đổi bởi một biến Cách gộp các biến biến rời rạc (ngày), (tháng), (năm) thành biến thời gian đầy đủ - date (ngày/tháng/năm) – Sử dụng Stata26/07/2012 08:58' PM Ở phần trước thongke.info đã giới thiệu tới các bạn cách chuyển biến dạng chữ (String variable) có chứa ngày tháng năm sang dạng ngày tháng năm chuẩn (date) trong Stata. Trong bài này, thongke.info xin giới thiệu cách các bạn cách gộp các biến biến rời rạc ea1(ngày), eb1(tháng), ec1(năm) thành biến date(ngày/tháng/năm) và cách tách biến ngày tháng năm chuẩn thành các biến rời rạc (ngày, tháng và năm) Trường hợp 1: Cách gộp các biến biến rời rạc ea1(ngày), eb1(tháng), ec1(năm) thành biến date(ngày/tháng/năm) Xử lý missing data sử dụng phương pháp MI – Multiple Imputation trong Stata26/07/2012 08:44' PM Trong bài “phương pháp xử lý giá trị missing trong stata” kì trước được trình bày trong mục “Phương pháp luận/quản lý, xử lý số liệu”, thongke.info đã giới thiệu 2 phương pháp xử lý giá trị missing: kiểm tra giá trị thực và thay thế giá trị missing và thay thế giá trị missing bằng các giá trị trung bình, trung vị. Trong bài “phương pháp xử lý giá trị missing trong stata” kì trước được trình bày trong mục “Phương pháp luận/quản lý, xử lý số liệu”, thongke.info đã giới thiệu 2 phương pháp xử lý giá trị missing: kiểm tra giá trị thực và thay thế giá trị missing và thay thế giá trị missing bằng các giá trị trung bình, trung vị.
Trong bài này, thongke.info giới thiệu với các bạn phương pháp dự đoán/ước tính giá trị missing – IMPUTATION dựa trên mô hình phân tích hồi quy đa biến, sử dụng phương pháp Multiple Imputation – MI trong Stata.
Chúng ta sẽ xem xét ví dụ: một chương trình can thiệp có mục tiêu nâng cao kiến thức phòng tránh HIV cho thanh thiếu niên đường phố. Chương trình thực hiện nghiên cứu tìm hiểu các yếu tố tác động đến kiến thức về HIV của thanh thiếu niên đường phố. Chuyển biến dạng chữ có chứa ngày tháng sang biến dạng ngày tháng trong Stata26/07/2012 08:19' PM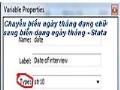 Ngày tháng năm (date) là một trong các dạng biến đặc biệt và quan trọng trong quá trình phân tích số liệu, nhất là trong các điều tra dinh dưỡng vì liên quan đến tuổi của bà mẹ, tuổi của trẻ nhỏ. Tuy nhiên trong quá trình thu thập số liệu hay nhập liệu thì biến ngày tháng đã không được định dạng đúng về dạng ngày tháng (date) mà lại ở dạng chữ (string) hay dạng số (numberic) do đó chúng ta không thể tính tuổi của ĐTNC (bà mẹ, trẻ nhỏ) hay những giá trị khác liên quan đến biến ngày tháng được. Phần này thongke.info xin giới thiệu tới các bạn cách để chuyển biến dạng chữ (String variable) có chứa ngày tháng năm sang dạng ngày tháng năm chuẩn (date) trong stata. Ngày tháng năm (date) là một trong các dạng biến đặc biệt và quan trọng trong quá trình phân tích số liệu, nhất là trong các điều tra dinh dưỡng vì liên quan đến tuổi của bà mẹ, tuổi của trẻ nhỏ. Tuy nhiên trong quá trình thu thập số liệu hay nhập liệu thì biến ngày tháng đã không được định dạng đúng về dạng ngày tháng (date) mà lại ở dạng chữ (string) hay dạng số (numberic) do đó chúng ta không thể tính tuổi của ĐTNC (bà mẹ, trẻ nhỏ) hay những giá trị khác liên quan đến biến ngày tháng được. Phần này thongke.info xin giới thiệu tới các bạn cách để chuyển biến dạng chữ (String variable) có chứa ngày tháng năm sang dạng ngày tháng năm chuẩn (date) trong stata.
Trường hợp 1: Biến ngày tháng dạng chữ (string variable có chứa 4 chữ cho trường năm, ví dụ 2007)
Ví dụ: biến date với format dạng chữ, có chứa số liệu ngày tháng như sau: | |
|

|
|
|
|
|
|
|
