Trong quá
trình thu thập số liệu, nhập liệu có những biến sẽ có giá trị missing. Nguyên
nhân có thể do phỏng vấn viên quên hỏi, do nhập liệu viên nhập sót hoặc do thiết
kế bộ câu hỏi có những câu hỏi chỉ dành riêng cho nhóm đối tượng nào đó. Ví dụ
như hỏi về việc chăm sóc thai nghén sẽ chỉ hỏi ở những người phụ nữ đã từng
mang thai, hay hỏi về sử dụng dịch vụ y tế trong 1 tháng qua thì sẽ chỉ hỏi với
những đối tượng đã đến cơ sở y tế 1 tháng qua… Chúng ta cần phát hiện và xử lý
các giá trị missing này để đảm bảo tính chính xác của các kết quả phân tích. a. Phát hiện các giá trị missing
Chúng ta có
rất nhiều cách để phát hiện giá trị missing của một hay nhiều biến. Các phát hiện
missing trong bài này bao gồm: sắp xếp biến, mô tả biến, liệt kê biến, đếm giá
trị missing.
codebook :
qid-mã bộ câu hỏi, a16b-mã xã, a17b-mã thôn, a19-dân tộc
*Lệnh sắp xếp biến
sort a19
(Thực hiện lệnh sort xong các bạn có thể vào
phần browse để xem các giá trị missing đã được sắp xếp trong bộ số liệu) 
*Mô tả
biến (bao gồm cả missing)
tab a19 , m 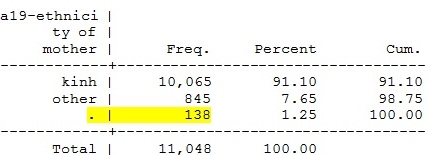
*Lệnh
liệt kê biến
list qid a16b a17b a19 if
a19==.
(Liệt kê các đặc điểm đi kèm của những bản
ghi không có thông tin về dân tộc của người trả lời) 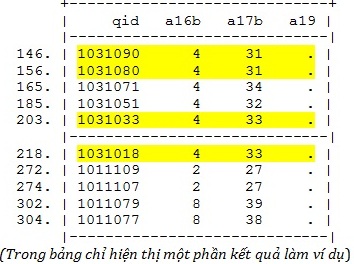
*Đếm giá trị missing Ta
có thể đếm các giá trị missing theo từng biến một bằng lệnh count hoặc đếm giá
trị missing của nhiều biến cách tạo ra biến tổng missing bằng lệnh egen cụ thể
như sau: count if a19==. 138 Đếm
các biến missing bằng lệnh egen, biến mới được tạo thành sẽ đến các giá trị
missing theo từng dòng egen somissing=rowmiss (a16b a17b
a19) tab somissing 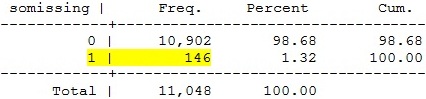
Phương pháp xử lý missing
Ba phương
pháp xử lý missing chính bao gồm: 1) Kiểm tra giá trị thực và thay thế giá trị missing: bằng cách
kiểm tra lại phiếu, kiểm tra lại với phỏng vấn viên, kiểm tra lại
với đối tượng nghiên cứu. 2)
Thay thế
giá trị missing bằng các giá trị trung bình, trung vị 3) Phương pháp dự đoán giá trị (IMPUTATION): dự đoán
giá trị missing đó dựa trên các giá trị khác. - Dự đoán
đơn giản: dựa trên giá trị của một số biến khác để dự đoán. Ví dụ
nếu một phiếu hỏi bị missing giá trị của biến giới tính, nếu các
biến khám phụ khoa, sinh con ở đâu có giá trị, ta có thể dự đoán
giới tính = nữ.
- Chạy các mô
hinh hồi quy để dự báo giá trị từ các biến liên quan
Việc quyết
định có thay thế giá trị missing hay không phụ thuộc vào bản chất
của biến bị missing và tỷ lệ missing. Với biến kết quả, nếu giá
trị missing 5-10% và cỡ mẫu đủ lớn, có thể không cần thay thế giá
trị missing/imputation. Nếu giá trị missing > 10% cần xem xét thay
thế giá trị missing/imputation. Trong nghiên
cứu có so sánh các đối tượng nghiên cứu tại các thời điểm, nếu
missing số liệu là do bị mất dấu đối tượng (lost of follow-up), Trước
khi quyết định thực hiện thay thế giá trị missing/imputation, nghiên
cứu viên cần chạy phân tích để xem xét xem có sự khác biệt (có ý
nghĩa thống kê) cho các biến quan trọng liên quan giữa nhóm đối tượng
missing số liệu và nhóm không mất số liệu. Nếu như khác biệt có ý
nghĩa thống kê thì phân tích so sánh cần được adjust cho sự khác biệt
này. *Thay thế giá trị missing bằng giá trị thực tế trong phiếu phỏng vấn
Ví du: sau
khi phát hiện missing ở biến a19, chúng ta kiểm tra lại các phiếu và thấy có
phiếu 1031090, 1031080, 1031033, 1031018 có thông tin a19=2, ta sẽ sửa lại
thông tin này trong bộ số liệu bằng lệnh replace.
replace a19=2 if qid==1031090|qid==1031080|qid==1031033|
qid==1031018
Kết quả sau
khi thay thế các giá trị missing
list qid a16b a17b a19 if qid==1031090|qid==1031080|qid==1031033| qid==1031018 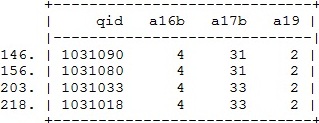
*Thay
thế giá trị missing bằng trung bình của biến
Ví dụ: Ta tìm hiểu các giá trị missing của biến b27-Số
ngày ở lại cơ sở y tế sau khi sinh
count if b27==.
287
Tính toán trung bình số ngày ở lại cơ sở y tế
sau khi sinh của các bà mẹ
mean b27 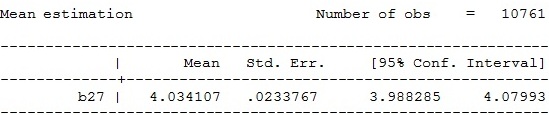
Thay thế các
giá trị missing của biến b27 bằng giá trị trung bình của biến b27
replace b27=4.034107 if b27==.
Chạy lại lệnh
kiểm tra missing
count if b27==. 0
*Thay thế giá trị missing bằng giá trị trung bình của phân nhóm
Đôi khi việc
sử dụng giá trị trung bình của biến để thay thế các giá trị missing sẽ không
phù hợp do sự khác nhau về đặc điểm của các nhóm đối tượng khác nhau. Lúc này
chúng ta có thể sử dụng các giá trị trung bình của phân nhóm để xử lý các giá
trị missing.
Các bước
thay thế giá trị missing bằng trung bình của phân nhóm được thực hiện tương tự
như thay thế missing bằng trung bình của biến. Cụ thể ta xem xét ví dụ sau
“Ví dụ như biến BMI của bà mẹ có một số giá
trị bị missing, nếu chúng ta chỉ sử dụng giá trị trung bình của biến BMI để
thay thế cho tất cả các quan sát bị missing sẽ không hợp lý do giữa các nhóm tuổi
có sự khác nhau về chỉ số BMI. Vì vậy cách hợp lý hơn là chúng ta sẽ xem xét
các giá trị trung bình của biến BMI theo nhóm tuổi và tiến hành thay thế giá trị
missing theo phân nhóm tuổi”.
Kiểm tra,
phát hiện các giá trị missing của biến BMI
count if BMI==.
16
sort age_cat
list age_cat BMI if BMI==. 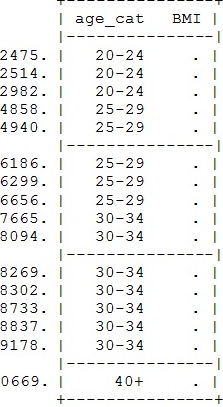
Tính toán giá trị trung bình của biến BMI
theo nhóm tuổi
mean BMI, over (age_cat) 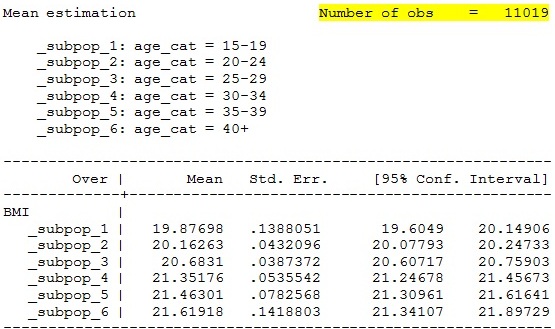
Thay thế các
giá trị missing bằng trung bình các phân nhóm
replace BMI=20.16263 if age_cat==2 & BMI==.
replace BMI=20.6831 if age_cat==3 & BMI==.
replace BMI=21.35176 if age_cat==4 & BMI==.
replace BMI=21.61918 if age_cat==6 & BMI==. Kết quả chạy
trung bình BMI theo nhóm tuổi sau khi đã xử lý missing
mean BMI, over (age_cat) 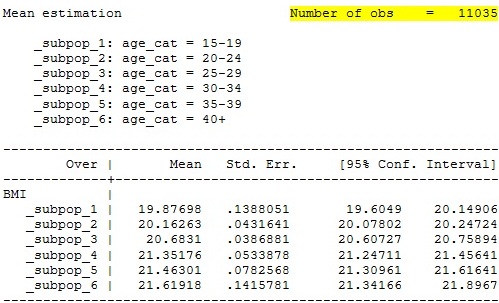
*Khi xử lý
các số liệu missing bạn nên tạo ra một biến mới bằng chính biến muốn xử lý để sau
này có thể đối chiếu và tránh làm mất số liệu gốc. Để làm điều này bạn chỉ cần
thực hiện lệnh đơn giản sau:
gen [tên biến gốc cần xử lý]=[biến mới]
Phương pháp dự đoán giá trị (IMPUTATION): dự đoán
giá trị missing đó dựa trên các giá trị khác (thongke.info sẽ giới
thiệu chi tiết trong một bài riêng biệt)
Dưới đây
là ví dụ một mô hình dự đoán việc bỏ thuốc lá (quitdate) ở các
đối tượng mất dấu tại thời điểm kết thúc dự án can thiệp phòng
chống thuốc lá. 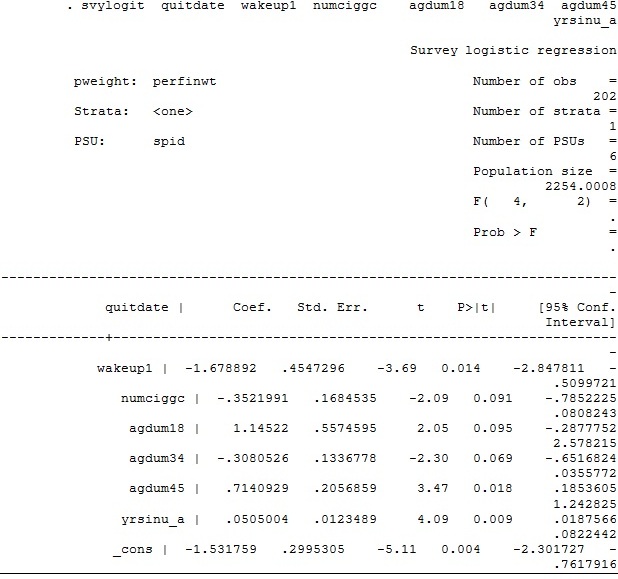
| 