|
Quản lý số liệu (Data management) |
   |
|
|
|
|
|
|

|
|
Phương pháp xóa bỏ biến trùng lặp trong Stata |
|
|

|

|
| Trang chủ
>
Quản lý, phân tích số liệu
>
Quản lý số liệu (Data management)
>
Xử lý số liệu
>
Xóa bỏ các biến trùng lặp (Remove character, duplicate or variable)
>
Phương pháp xóa bỏ biến trùng lặp trong Stata | Phương pháp xóa bỏ biến trùng lặp trong Stata | Trong quá trình nhập liệu, hoặc nối, gộp các file số liệu có thể dẫn đến nhiều biến, bản ghi trùng lặp, đặc biệt là với số lượng biến lớn thì sẽ xử lý như thế nào? Thongke.info xin giới thiệu với các bạn các lệnh syntax mẫu để tìm, và xóa các biến, bản ghi trùng lặp. Để tìm hiểu kĩ hơn về cách loại bỏ các biến/quan sát trùng lặp ta theo dõi cụ thể ví dụ sau.
Ví dụ: Ta có bộ số liệu sau
Codebook: a1-Tên loại hoa quả, a2-Số lượng (kg), a3-Giá tiền/kg (nghìn đồng)
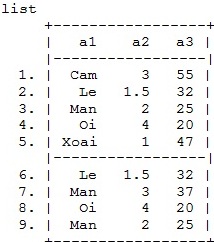
1. Loại bỏ các quan sát trùng lặp với 1 hoặc một nhóm biến chỉ thị
Ví dụ1: Ta muốn loại bỏ các quan sát trùng lặp của biến a1-Tên loại hoa quả.
Đầu tiên để xác định quan sát trùng lặp ta dùng lệnh sort để sắp xếp biến, cụ thể ở đây ta sẽ sắp xếp biến a1. Sau đó ta sẽ dùng câu lệnh để tạo ra biến xác định sự trùng lặp theo cú pháp sau:
sort a1
quiet by a1: gen dup= cond(_N==1,0,_n)
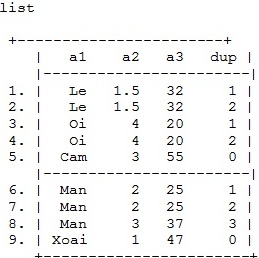
Lúc này bộ số liệu của chúng ta được sắp xếp và trình bày như sau:
Biến dup là biến chỉ thị cho chúng ta biết về mức độ trùng lặp của các quan sát chúng ta đang xem xét:
dup=0 – quan sát duy nhất
dup=1 – có 1 quan sát trùng
dup=2- có 2 quan sát trùng
dup=n –có n quan sát trùng
Nhìn vào kết quả sắp xếp ta thấy Lê, Mận, Ổi là những loại hoa quả đang bị lặp lại. Nếu ta muốn loại bỏ các biến trùng lặp ta chỉ cần sử dụng lệnh xóa biến.
drop if dup>1
(nếu muốn giữ lại 1 quan sát)
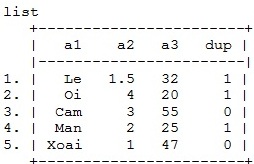
drop if dup>0
(nếu không muốn giữ lại quan sát nào)

2. Loại bỏ các quan sát trùng lặp với tất cả các biến chỉ thị:
Trong một số trường hợp bạn nhận thấy dựa vào một hay một vài biến chỉ thị để loại bỏ các quan sát bị trùng nhau như ví dụ 1 sẽ khó khăn hoặc chưa phù hợp. Bạn có thể sử dụng dùng cách thứ hai là loại bỏ biến dựa trên tất cả các biến chỉ thị.
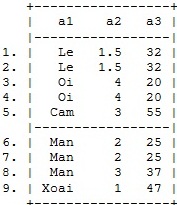
Đầu tiên ta cần đưa tất cả các biến chỉ thị về một chuỗi biến lớn để có thể tiến hành sắp xếp các biến bằng cú pháp sau:
unab vlist : _all
sort `vlist ’
Ta được kết quả sắp xếp sau.
Chạy lệnh tạo biến chỉ thị sự trùng lặp quietly by `vlist': gen dup = cond(_N==1,0,_n) 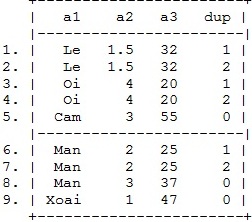
Loại bỏ biến trùng lặp drop if dup >1 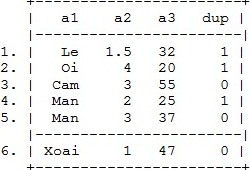
drop if dup >0 
Số lượt đọc:
6390
-
Cập nhật lần cuối:
04/07/2012 09:16:51 AM |
|

|
|
|
|
|
|
|
